
{kind=link}
Semrush không crawl website được khiến bạn không thể audit lỗi kỹ thuật, không phát hiện vấn đề SEO quan trọng và làm sai lệch chiến lược? Bài viết này giúp bạn hiểu rõ nguyên nhân và hướng dẫn cách kiểm tra, khắc phục chính xác từng trường hợp.
Khi Semrush không crawl website được: vấn đề tưởng nhỏ nhưng ảnh hưởng lớn đến toàn bộ chiến lược SEO
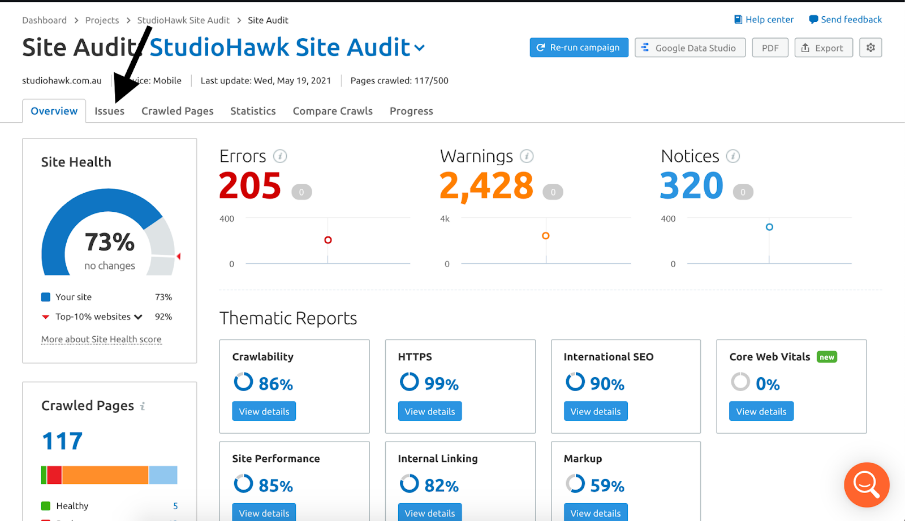
Trong quá trình làm SEO kỹ thuật, việc sử dụng Semrush Site Audit để crawl website nhằm phát hiện lỗi liên quan đến indexability, internal link, redirect, cấu trúc trang và các vấn đề kỹ thuật khác được xem là một bước nền tảng không thể thiếu, tuy nhiên rất nhiều người gặp phải tình huống project chạy xong nhưng số lượng URL được crawl lại cực kỳ ít hoặc thậm chí bằng không, điều này không chỉ gây khó khăn trong việc phân tích mà còn dẫn đến những quyết định sai lầm trong chiến lược SEO nếu không hiểu đúng bản chất vấn đề.
Điểm quan trọng cần nhận thức rõ là trong phần lớn các trường hợp, lỗi Semrush không crawl được website không phải xuất phát từ công cụ mà lại đến từ chính website hoặc cách cấu hình crawl, bởi vì Semrush hoạt động dựa trên cơ chế crawler tương tự như Googlebot và không có bất kỳ quyền truy cập đặc biệt nào vào hệ thống của bạn, điều này đồng nghĩa với việc nếu website chặn bot hoặc cấu hình sai thì việc crawl thất bại là điều hoàn toàn dễ hiểu.
Semrush crawl website như thế nào và vì sao bạn cần hiểu rõ cơ chế này
Semrush Site Audit hoạt động dựa trên cơ chế crawler giống Googlebot
Semrush Site Audit thực chất là một crawler tự động gửi request đến website của bạn, đọc HTML, phát hiện các liên kết nội bộ và tiếp tục truy cập sang các URL mới theo cấu trúc liên kết, quá trình này diễn ra theo logic tương tự như Googlebot, nghĩa là bot không “nhìn thấy” website theo cách người dùng nhìn thấy mà phụ thuộc hoàn toàn vào khả năng truy cập kỹ thuật của hệ thống.
Theo tài liệu chính thức của Semrush, bạn có thể cấu hình nguồn crawl khác nhau như crawl theo website, crawl theo sitemap, crawl theo robots.txt hoặc upload danh sách URL thủ công, và chỉ cần bạn chọn sai nguồn hoặc giới hạn số lượng URL crawl quá thấp thì kết quả audit sẽ không phản ánh đúng thực tế của website.
SemrushBot là gì và tại sao nó có thể bị chặn
Semrush sử dụng một crawler riêng có tên là SemrushBot, đây là một user-agent được nhận diện giống như các bot khác và hoàn toàn có thể bị hệ thống bảo mật của website chặn lại nếu bị coi là truy cập không mong muốn.
Cách SemrushBot hoạt động và danh sách user-agent liên quan, từ đó nhận ra rằng việc website vẫn truy cập bình thường đối với người dùng nhưng Semrush không crawl được là một tình huống hoàn toàn hợp lý nếu bot bị hạn chế.
10 nguyên nhân phổ biến khiến Semrush không crawl được website mà bạn cần kiểm tra theo thứ tự ưu tiên
1. Robots.txt đang chặn toàn bộ hoặc chặn nhầm SemrushBot
Robots.txt là lớp kiểm soát crawl đầu tiên và cũng là nguyên nhân phổ biến nhất khiến Semrush không thể truy cập website, đặc biệt khi website mới triển khai hoặc đang trong giai đoạn phát triển thường có cấu hình chặn bot để tránh index sớm.
Ví dụ đơn giản như dòng Disallow toàn bộ website sẽ khiến mọi crawler bị chặn ngay lập tức, và theo tài liệu Google thì robots.txt có vai trò kiểm soát việc crawl chứ không phải index, do đó nếu cấu hình sai bạn có thể vô tình chặn toàn bộ quá trình audit.
2. Robots.txt trả về lỗi 5xx khiến crawler dừng hoạt động
Một lỗi ít được chú ý nhưng lại cực kỳ nghiêm trọng là khi file robots.txt không trả về mã 200 mà trả về lỗi server như 500 hoặc 503, trong trường hợp này Semrush có thể hiểu rằng không thể truy cập file robots và dừng crawl toàn bộ website để tránh rủi ro.
3. Firewall, CDN hoặc hệ thống bảo mật đang chặn bot
Các hệ thống như Cloudflare, tường lửa server hoặc plugin bảo mật trên CMS có thể tự động chặn các bot nếu phát hiện hành vi crawl liên tục hoặc nghi ngờ là tấn công, điều này thường xảy ra khi crawl speed cao hoặc server không đủ tài nguyên.
Trong trường hợp này, SemrushBot sẽ không thể truy cập dù website vẫn hoạt động bình thường với người dùng.
4. Website yêu cầu đăng nhập hoặc bị giới hạn truy cập
Những website dạng staging, intranet hoặc có hệ thống membership thường yêu cầu đăng nhập hoặc giới hạn truy cập theo IP, điều này khiến crawler không thể truy cập nội dung và dẫn đến việc không crawl được website.
5. Cấu hình Site Audit sai ngay từ đầu
Nhiều người không để ý rằng lỗi có thể đến từ chính cách cấu hình project trong Semrush, ví dụ như giới hạn crawl chỉ 100 URL trong khi website có hàng nghìn trang, hoặc chọn crawl từ sitemap nhưng sitemap lại không đầy đủ URL, hoặc thiết lập include/exclude rule sai khiến bot không đi đúng hướng.
6. Website sử dụng JavaScript mạnh khiến crawler không đọc được nội dung
Các website hiện đại sử dụng framework như React hoặc Vue thường render nội dung bằng JavaScript, điều này khiến crawler khó phát hiện liên kết nội bộ hoặc nội dung trang nếu không được tối ưu render, dẫn đến việc crawl bị giới hạn.
7. Lỗi DNS hoặc website đang offline
Nếu domain không resolve được DNS hoặc server đang downtime, Semrush sẽ không thể gửi request đến website và kết quả là không crawl được dữ liệu.
8. Trang quá nặng hoặc server phản hồi chậm
Nếu thời gian phản hồi server quá lâu hoặc dung lượng trang quá lớn, crawler có thể timeout và bỏ qua trang, điều này đặc biệt phổ biến với các website chưa tối ưu hiệu suất.
9. Cấu trúc internal link yếu hoặc thiếu liên kết
Nếu website không có hệ thống liên kết nội bộ rõ ràng hoặc các trang quan trọng không được liên kết, crawler sẽ không thể tìm thấy các URL đó và dừng crawl sớm.
10. Redirect loop, lỗi 404, 500 hoặc lỗi truy cập URL
Các lỗi kỹ thuật như redirect loop hoặc chain dài có thể khiến crawler không đến được trang đích, trong khi các lỗi 4xx và 5xx khiến bot bỏ qua URL hoàn toàn.
Quy trình kiểm tra Semrush không crawl được website theo từng bước rõ ràng
Bước 1: Kiểm tra số lượng URL đã crawl
Bạn cần so sánh số URL Semrush crawl được với quy mô thực tế của website, nếu chênh lệch lớn thì chắc chắn có vấn đề cần xử lý.
Bước 2: Kiểm tra Issues Report và Crawled Pages
Semrush cung cấp báo cáo chi tiết, nơi bạn có thể lọc các URL bị block, lỗi hoặc redirect để xác định nguyên nhân.
Bước 3: Kiểm tra robots.txt trực tiếp
Truy cập file robots.txt của website và kiểm tra:
- Disallow
- User-agent
- Status code
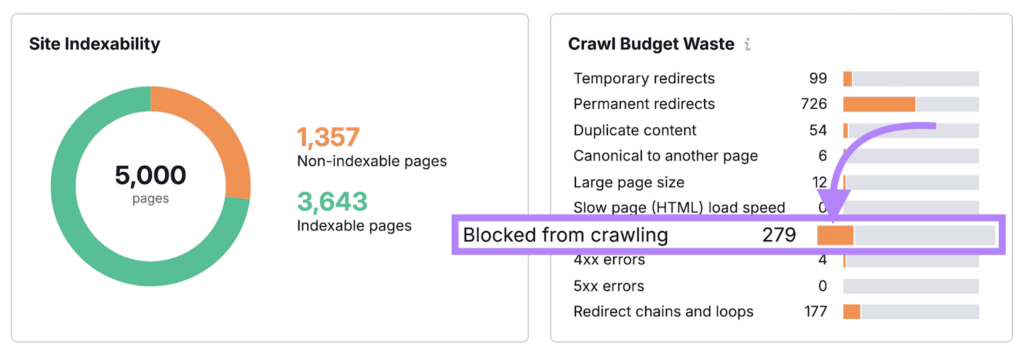
Bước 4: Kiểm tra source code và header
Bạn cần kiểm tra các yếu tố như noindex, canonical hoặc x-robots-tag theo hướng dẫn của Google.
Bước 5: Kiểm tra DNS, hosting và trạng thái website
Đảm bảo rằng website có thể truy cập công khai, không bị downtime và không bị giới hạn truy cập.
Bước 6: Kiểm tra firewall và log server
Nếu có quyền truy cập server, bạn nên kiểm tra log để xác định SemrushBot có bị chặn hay không.
Bước 7: Kiểm tra sitemap và internal link
Sitemap cần đầy đủ URL và hỗ trợ crawler, theo hướng dẫn tại đây, tuy nhiên cần nhớ rằng sitemap chỉ là tín hiệu hỗ trợ chứ không đảm bảo crawl.
Cách khắc phục Semrush không crawl được website theo từng trường hợp cụ thể
Sửa robots.txt đúng cách và tránh chặn nhầm
Bạn nên đảm bảo rằng robots.txt không chặn toàn bộ website và chỉ giới hạn những khu vực không cần crawl.
Whitelist SemrushBot trong firewall hoặc CDN
Nếu sử dụng hệ thống bảo mật, bạn cần cho phép SemrushBot truy cập hoặc giảm tốc độ crawl để tránh bị chặn.
Tối ưu cấu hình Site Audit
Hãy kiểm tra lại:
- Crawl limit
- Crawl source
- Include/exclude rule

Tối ưu JavaScript để crawler đọc được nội dung
Bạn có thể sử dụng server-side rendering hoặc đảm bảo liên kết nội bộ không phụ thuộc hoàn toàn vào JavaScript.
Tối ưu hiệu suất website
Giảm thời gian phản hồi server và tối ưu tài nguyên để tránh timeout.
Cải thiện hệ thống internal link
Tăng liên kết nội bộ giúp crawler dễ dàng tìm và crawl toàn bộ website.
Mua Tài khoản Semrush Pro chính hãng giá rẻ tại CentriX
Nếu bạn muốn sử dụng tài khoản Semrush Pro với chi phí hợp lý, có thể tham khảo nền tảng cung cấp phần mềm bản quyền uy tín như CentriX
CentriX là nền tảng chuyên cung cấp:
- Phần mềm bản quyền
- Tài khoản AI
- Ứng dụng học tập
- Microsoft 365
Kết luận
Semrush không crawl được website không phải là lỗi hiếm mà là một trong những vấn đề phổ biến nhất trong SEO kỹ thuật, tuy nhiên nếu bạn hiểu rõ cách crawler hoạt động và kiểm tra theo đúng quy trình, bạn hoàn toàn có thể xác định chính xác nguyên nhân và khắc phục một cách hiệu quả.
Điều quan trọng không nằm ở việc tìm một giải pháp chung mà là hiểu rằng mỗi nguyên nhân sẽ dẫn đến một cách xử lý khác nhau, và chỉ khi bạn nắm được bản chất của crawl thì bạn mới có thể tối ưu website một cách bền vững và chính xác, thay vì chỉ xử lý theo cảm tính hoặc thử sai liên tục.
Xem thêm: Semrush không hiển thị dữ liệu, nguyên nhân là gì và sửa thế nào